Reworking JoinOrder around the IMDb 2013 dataset¶
The Join Order Benchmark evaluates query optimizers against the skewed, correlated distributions in the IMDb 2013 dataset. BenchBox v0.3.0 updates
joinorderso its data contract reflects that benchmark target.
TL;DR: A community report showed that BenchBox’s old JoinOrder data did not preserve the IMDb relationships and distributions that make the Join Order Benchmark useful. The release updates joinorder to use the IMDb 2013 JOB dataset at scale factor 1, adds all 113 JOB SQL queries, records dataset identity in result bundles, and moves the old generated data to joinorder_synthetic.
On May 9, 2026, GitHub user @partychicken filed issue #289 against BenchBox.[1] The report was about the benchmark contract: BenchBox had a JoinOrder-shaped workload (the schema, queries wired through the framework, and generated data for smoke tests), but the data was not the IMDb dataset used by the Join Order Benchmark papers. With generated data that does not preserve those IMDb correlations, optimizer estimates can appear more accurate because the workload no longer contains the dependency patterns JOB was selected to expose.
v0.3.0 corrects that contract. joinorder now identifies the real IMDb 2013 Join Order Benchmark dataset, at one fixed scale. The old generated workload is still useful for development, but it has a different name and is not published JOB evidence. Throughout this post, “canonical” means the reference JOB data contract: the fixed IMDb 2013 dataset and the 113-query workload used by the JOB papers, not any future reduced dataset, generated test fixture, or schema-compatible approximation.
Why the IMDb data matters for JOB¶
The original JOB paper, “How Good Are Query Optimizers, Really?”, chose IMDb deliberately.[2] The follow-up VLDB Journal paper kept that focus on optimizer behavior over real application data.[3] IMDb data has skew, correlations, and uneven distributions: exactly the properties that make cardinality estimates fail in ways JOB is designed to surface.
If an optimizer assumes predicates are independent when the IMDb data shows otherwise, cardinality estimates can drift enough to produce a suboptimal join order. JOB is designed to make that failure mode visible. Uniformly random synthetic data weakens the test: independence assumptions become accidentally accurate, and queries can complete successfully while no longer exercising the intended optimizer challenge.
Issue #289 stated the consequence directly:
In other words, uniform random generation removes the very property that JOB was designed to test.
BenchBox’s generated data still had engineering value. It helped exercise loaders, table creation, query registration, and basic platform tests. But it was not a comparable JOB run, and the report proposed the appropriate scope of fix:
What the report asked for |
What v0.3.0 ships |
|---|---|
Disable synthetic scaling for JOB |
|
Use the original frozen IMDb dataset |
|
Keep JOB faithful to its purpose |
All 113 JOB SQL queries are embedded and checked |
Avoid misleading results |
The generated workload is renamed |
The report forced a useful distinction: schema-compatible data is not the same thing as benchmark-compatible data.
Why scale factor 1 is intentional¶
Most BenchBox benchmarks support scale factors because the data generator can produce a smaller or larger version of the workload, which makes iteration easier and lets users run smoke tests before larger runs.
JoinOrder is different. The public benchmark now uses a fixed IMDb-derived dataset, which is why joinorder --scale 0.01 is not part of v0.3.0. A smaller public JOB workload would need more than fewer rows:
correlated data that preserves the properties JOB is meant to expose
reference cardinalities for the smaller data
clear labeling so users do not compare it with full JOB
a stable data-delivery contract
tests that prove the query semantics still match the intended workload
Without those pieces, a smaller workload would create a false sense of comparability: fast and convenient, but not the Join Order Benchmark as defined by the published JOB workload. The generated data remains useful for development and smoke-test coverage; the explicit joinorder_synthetic name keeps it from being confused with comparable benchmark data.
What the reference dataset means in BenchBox¶
In v0.3.0, the reference JoinOrder dataset means three things.
First, the dataset is fixed. BenchBox’s package is derived from the Harvard Dataverse imdb_pg11 archive, DOI 10.7910/DVN/2QYZBT, restored into PostgreSQL and converted to the 21-table JOB schema. The manifest identifies the BenchBox data contract as:
dataset_version = "joinorder-imdb-2013-v1"
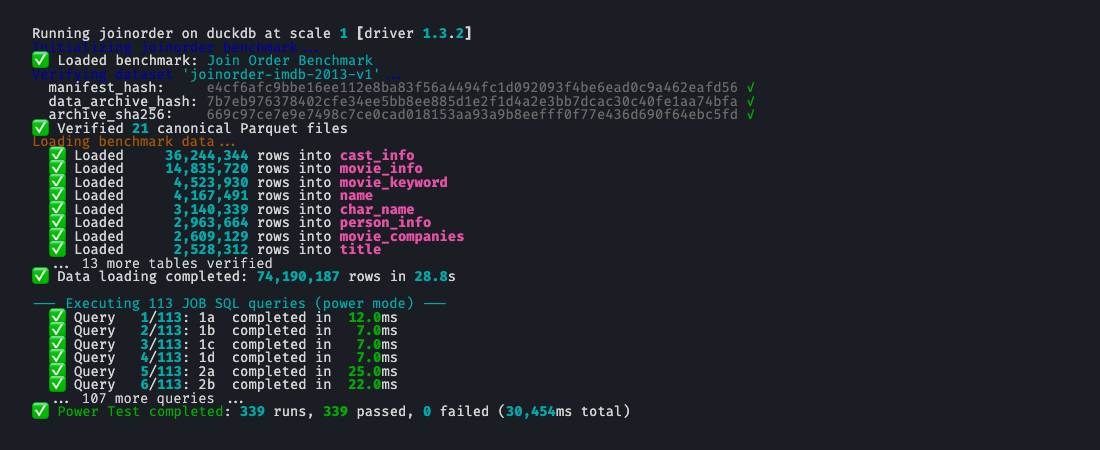
Second, the archive is verified. BenchBox checks the downloadable archive, extracted table hashes, and row counts, then records manifest-backed identity fields so result bundles can identify which data contract they used.
Third, the dataset is structured as the 21-table JOB schema. The largest table, cast_info, has 36,244,344 rows. The full table list and per-table hashes live in the data manifest rather than in this post, because the manifest is the durable source of truth.
This is not a legal claim about IMDb redistribution. It is an engineering statement about data identity: BenchBox can say which dataset version a result used, which manifest described it, and which logical archive content was verified.
Query coverage changed too¶
The data change would be incomplete without the query set. v0.3.0 includes all 113 JOB SQL queries, with IDs in the familiar JOB shape (such as 1a, 2b, and 15a). The test suite checks that all 113 queries are registered and parse as PostgreSQL-flavored SQL.
The release also adds reference cardinalities and predicate-focused fixture tests. Those checks protect the two most important parts of the benchmark:
The query catalog must contain the workload users expect.
The predicates must keep the intended semantics as the code evolves.
DataFrame query coverage exists for the same query IDs, with one important boundary: SQL joinorder stresses optimizer join-order planning, while DataFrame joinorder executes explicit join sequences through platform DataFrame APIs. Query ID coverage is useful for workload breadth, but it is not the same as comparable optimizer evidence.
Result identity is part of the fix¶
Once a benchmark depends on a fixed external dataset, result identity matters more. A timing number without the data contract is not auditable later, and unauditable benchmark numbers make later comparisons hard to resolve.
v0.3.0 adds three fields that result bundles can use for manifest-backed datasets:
dataset_version: the named data contractmanifest_hash: the manifest that described the expected datadata_archive_hash: the logical archive content
For JoinOrder, these fields separate three cases that should not be mixed:
old BenchBox generated data
the real IMDb 2013 JOB dataset
any future reduced or alternate dataset, if one is ever added
The fields do not replace full methodology: hardware, platform version, adapter configuration, query selection, concurrency, and measurement mode still matter. They remove one common ambiguity by showing which data contract a result used.
Provenance and redistribution¶
v0.3.0 treats the current re-hosted Parquet archive as a documented redistribution-risk decision, not as BenchBox-cleared for broad commercial redistribution. The decision is documented alongside the dataset version, archive hash, manifest hash, Dataverse source, and IMDb attribution, so users understand what is being downloaded and measured.
Stricter approaches we may consider later:
written permission for the redistributed archive
direct Dataverse fetch with local conversion
a bring-your-own dataset path for environments with stricter policies
These would improve the provenance story, but they also add setup cost. For v0.3.0, the default path prioritizes a verified first run against the real JOB dataset. Users in stricter redistribution environments should review benchbox/core/joinorder/DATA-LICENSE.md and the documented BYO data path before relying on the default hosted archive.
What users need to change¶
If you ran JoinOrder before v0.3.0, treat those results as generated-data results. Do not compare them directly with v0.3.0 joinorder results.
The new command is straightforward:
uv add "benchbox[duckdb]"
uv run benchbox run --platform duckdb --benchmark joinorder --scale 1
The first run downloads and verifies the dataset before executing queries.
If your automation used a smaller JoinOrder scale, update it. joinorder now accepts only scale factor 1. If you need generated data for development or smoke coverage, use the explicitly named synthetic workload instead of publishing those numbers as JOB results.
What we learned¶
The main lesson is simple: benchmark names define contracts. When users see joinorder, they bring expectations from the JOB papers: a workload shaped by IMDb-derived skew and correlations, not just tables with familiar names. Generated data can be useful, but if it does not preserve the property the benchmark exists to test, it needs a different label.
There is also a provenance lesson worth calling out: dataset version, manifest hash, and archive hash are easy to overlook until someone asks why two published results disagree. They matter when an auditor needs to reconstruct the data contract behind a result.
The implementation adds more than the initial report requested, especially around dataset identity, but the core correction is the one issue #289 identified. If you use JoinOrder to evaluate optimizers, upgrade with care: pre-v0.3.0 results were generated-data results and should not be compared directly with new IMDb-backed runs; the new joinorder is a stricter baseline.
References¶
JoinOrder paper: How Good Are Query Optimizers, Really?
JoinOrder follow-up paper: Query Optimization Through the Looking Glass, and What We Found Running the Join Order Benchmark
Query corpus: gregrahn/join-order-benchmark
Dataset DOI: 10.7910/DVN/2QYZBT
Changelog entry:
CHANGELOG.md([0.3.0] - 2026-05-16)JoinOrder benchmark docs:
docs/benchmarks/join-order.md,docs/reference/python-api/benchmarks/joinorder.rstJoinOrder data manifest:
benchbox/core/joinorder/data_manifest.tomlJoinOrder data license note:
benchbox/core/joinorder/DATA-LICENSE.mdJoinOrder licensing decision:
_project/decisions/joinorder-canonical-data-licensing-2026-05-12.mdRelease overview: BenchBox v0.3.0: JoinOrder fix, approximate analytics, and agent prompt composer